- Go 100%
| benchmarks.jpg | ||
| go.mod | ||
| hilbert.go | ||
| LICENSE.md | ||
| README.md | ||
| spatial_index_2d.go | ||
{kind=link}
modular-spatial-index

For the demo that this animated gif was generated from, see: https://git.sequentialread.com/forest/modular-spatial-index-demo-opengl
modular-spatial-index is a simple spatial index adapter for key/value databases like leveldb and Cassandra (or RDBMS like SQLite/Postgres if you want), based on https://github.com/google/hilbert.
It's called "modular" because it doesn't have any indexing logic inside, you bring your own index. It simply defines a mapping from two-dimensional space ([x,y] as integers) to 1-dimensional space (a single string of bytes for a point, or a handful of byte-ranges for a rectangle). You can use these strings of bytes (keys) and byte-ranges (query parameters) in any database to implement a spatial index.
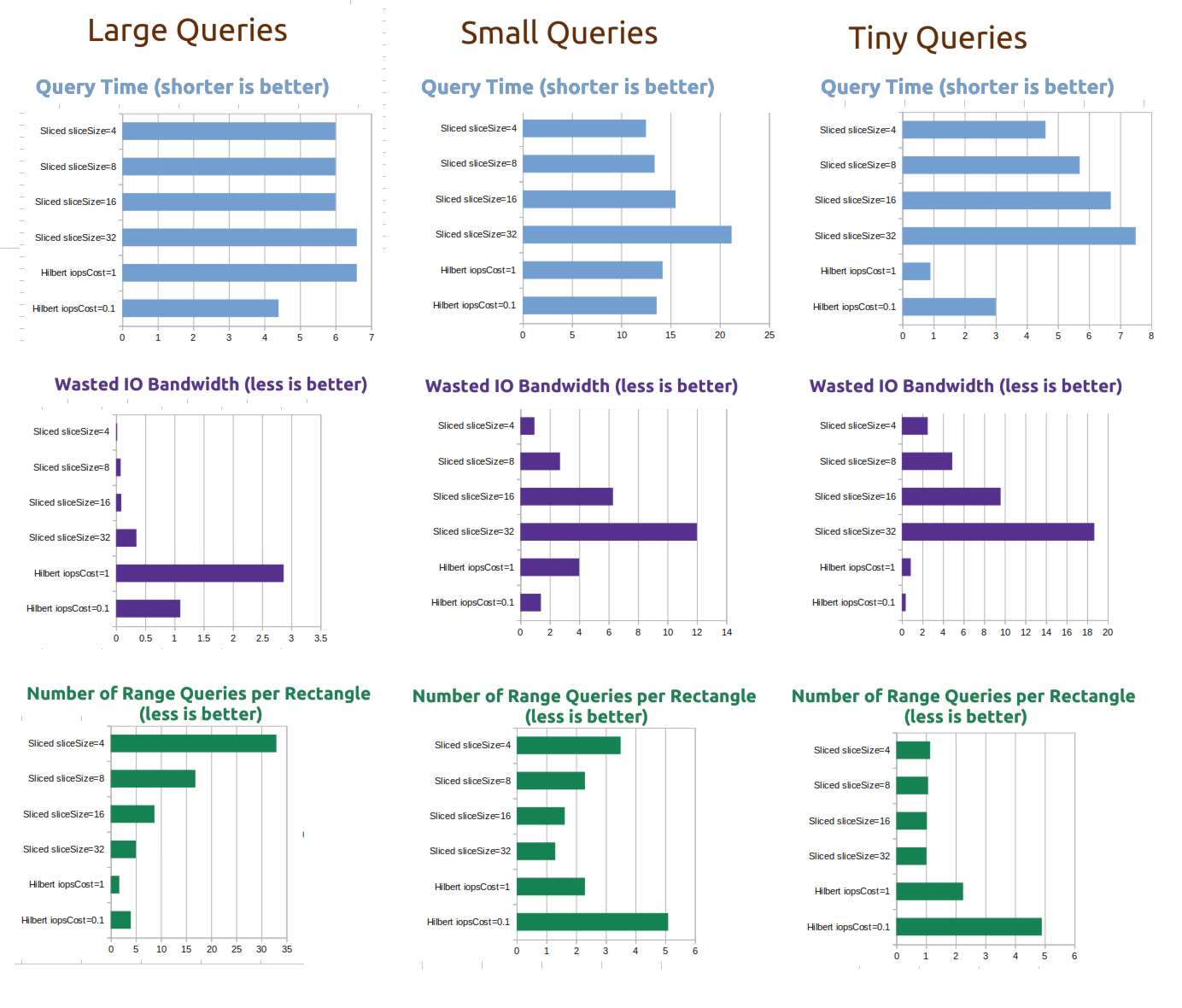
Read amplification for range queries is ~2x-3x in terms of IOPS and bandwidth compared to a 1-dimensional query.
But that constant factor on top of your fast key/value database is a low price to pay for a whole new dimension, right? It's certainly better than the naive approach.
See https://sequentialread.com/building-a-spatial-index-supporting-range-query-using-space-filling-hilbert-curve for more information.
Benchmarks
The benchmarks are part of the demo repository.
I benchmarked the spatial index against a tuned version of the "One range query for every row in the rectangle" approach I talk about in my blog post linked above, which I am calling the Sliced index, with various slice sizes.
For a test dataset, I used goleveldb to store approximately 1 million keys, each with a 4-kilobyte random value. During the benchmarks, each database index was approximately 3.5GB in size, and the test application was consuming about 30MB of memory.
Implementation example
See writing keys and querying an area.
Note regarding sillyHilbertOptimizationOffset: The hilbert curve has some rough edges around the center of the curve plane at [0,0], so you will hit worse-case performance (about 3x slower than best case) around there. In my app I simply offset the universe a bit to avoid this.
If your database doesn't support arbitrary byte arrays as keys and values, you can simply convert the byte arrays to strings, as long as the sort order is preserved.
Interface
NewSpatialIndex2D
// This is the only way to create an instance of SpatialIndex2D. integerBits must be 32 or 64.
// To use the int size of whatever processor you happen to be running on, like what golang itself does
// with the `int` type, you may simply pass in `bits.UintSize`.
NewSpatialIndex2D(integerBits int) (*SpatialIndex2D, error) { ... }
SpatialIndex2D.GetValidInputRange
// returns the minimum and maximum values for x and y coordinates passed into the index.
// 64-bit SpatialIndex2D: -1073741823, 1073741823
// 32-bit SpatialIndex2D: -16383, 16383
(index *SpatialIndex2D) GetValidInputRange() (int, int) { ... }
SpatialIndex2D.GetOutputRange
// returns two byte slices of length 8, one representing the smallest key in the index
// and the other representing the largest possible key in the index
// returns (as hex) 0000000000000000, 4000000000000000
// 32-bit SpatialIndex2Ds always leave the last 4 bytes blank.
(index *SpatialIndex2D) GetOutputRange() ([]byte, []byte) { ... }
SpatialIndex2D.GetIndexedPoint
// Returns a slice of 8 bytes which can be used as a key in a database index,
// to be spatial-range-queried by RectangleToIndexedRanges
(index *SpatialIndex2D) GetIndexedPoint(x int, y int) ([]byte, error) { ... }
SpatialIndex2D.GetPositionFromIndexedPoint
// inverse of GetIndexedPoint. Return [x,y] position from an 8-byte spatial index key
(index *SpatialIndex2D) GetPositionFromIndexedPoint(indexedPoint []byte) (int, int, error) { ... }
SpatialIndex2D.RectangleToIndexedRanges
// Returns a slice of 1 or more byte ranges (typically 1-4).
// The union of the results of database range queries over these ranges will contain AT LEAST
// all GetIndexedPoint(x,y) keys present within the rectangle defined by [x,y,width,height].
//
// The results will probably also contain records outside the rectangle, it's up to you to filter them out.
//
// iopsCostParam allows you to adjust a tradeoff between wasted I/O bandwidth and # of individual I/O operations.
// I think 1.0 is actually a very reasonable value to use for SSD & HDD
// (waste ~50% of bandwidth, save a lot of unneccessary I/O operations)
// if you have an extremely fast NVME SSD with a good driver, you might try 0.5 or 0.1, but I doubt it will make it any faster.
// 2 is probably way too much for any modern disk to benefit from, unless your data is VERY sparse
(index *SpatialIndex2D) RectangleToIndexedRanges(x, y, width, height int, iopsCostParam float32) ([]ByteRange, error) { ... }
ByteRange
// Use this with a range query on a database index.
type ByteRange struct {
Start []byte
End []byte
}
MIT license